

My team is responsible for automation tooling and monitoring of our hybrid multicloud platform within NetApp. When it comes to cloud automation, the first question asked is how fast we can provision an entire application stack with little or no human effort. This is quickly followed by a discussion around the “exit strategy” and the importance of cleaning up applications no longer needed.
Many cloud automation blogs focus on how to reduce the amount of provisioning time from days down to hours to even minutes. The same can be said for the deprovisioning process. But what about the rest of the efforts that happen during the application lifecycle? For example, the proper configuration item (CI) updates in the CMDB or the implementation of approval workflows so budgetary owners pay for the provisioned resources.
Interestingly, the provisioning and deprovisioning—along with all the workflows and automations that come with it—are only a small fraction, if not the smallest fraction—of the lifecycle when it comes to the managing provisioned resources. The most impactful work happens between these two and I’d like to share some of our key approaches.
Innovate, integrate and automate
Like other enterprises, we spent significant time looking for that one magic bullet tool to serve as a single pane of glass. One tool to provide visibility into the health of our environment, from infrastructure up to the application stack. After many reviews and POCs of various tools, we realized that the perfect tool did not exist, or at least one that would meet our needs. Instead, we decided to focus on integrating tools to create something more powerful than the sum of its parts.
As a by-product of this approach, we realized the importance of innovating, integrating and automating. For example, innovating in ways that the vendors may not have meant for the tool to be used, integrating by combining features from different tools, and automating it all into an environment that is low touch and reduces troubleshooting and mean time to recovery (MTTR). This approach challenged my team to go beyond conventional thinking and get creative in identifying possibilities.
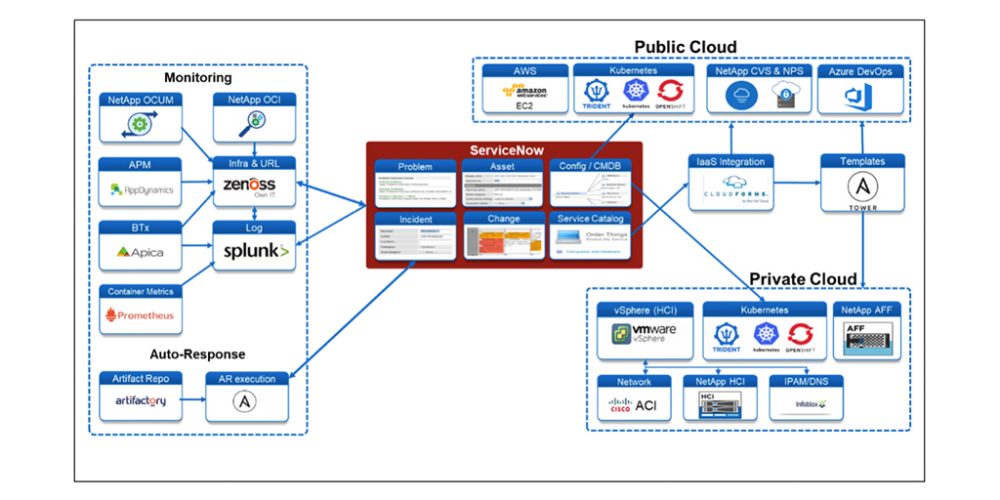
As shown in Figure 1, NetApp IT has an automation architecture that includes monitoring and auto-response with ServiceNow at its heart. Regardless if our resources are on or off premises, private or public cloud, we provide IT governance oversight to ensure our investments and services support business objectives. Today all governance is managed via ServiceNow, including the management of incidents, problems, and changes, our CMDB and service catalog, project and portfolio management.
Monitoring
We have several different monitoring tools in our automation technology ecosystem that integrate with ServiceNow. Other tools provide monitoring for storage NetApp Active IQ Unified Manager (OCUM) and NetApp OnCommand Insight (OCI), compute infrastructure (Zenoss), application performance (AppDynamics), and synthetic transactions (Apica), as well as providing insights into the containerized environment with a combination of Prometheus and Splunk.
The main repository of the events generated by these tools are sent to Zenoss and Splunk. The advantages of Zenoss is its ability to input events upstream from other tools and downstream into ServiceNow for automated ticket creation. We also feed data into Splunk to leverage its ability to aggregate and analyze machine data. Splunk also underpins our Application Centric Dashboard which receives information from different sources and holistically monitors and reports the health of our major Tier 1 applications from the infrastructure level up into the application stack.
Auto-Response
By staying true to our philosophy of innovate, integrate, and automate different tools to create something more powerful than the sum of its parts, we have expanded into automated response management. We began by looking at certain scenarios where automation could be used to rectify or facilitate information gathering before a ticket is sent to support.
One common use case of auto-response is the application process restart. When a ticket is identified for an application problem that requires a process restart, a script is triggered to restart the service. We have the ability at the application level within our CMDB (in ServiceNow) to see what infrastructure components are used by the application. By having visibility down to the asset level in the CMDB, we can ascertain which server(s) supports a business application. If an application runs on multiple servers, we can confidently automate a reboot or restart an application process on one server in the pool when necessary. Read this NetApp IT blog on “How Automated Response Takes Pressure Off IT Tech Support” to get more information.
Public and Private Cloud
ServiceNow also integrates with CloudForms and Ansible to automatically provision our private cloud leveraging NetApp HCI and All Flash FAS storage, and the public cloud (currently AWS) leveraging NetApp Cloud Volumes as well as NetApp Private Storage. NetApp Trident is used to provision persistent volumes in our Openshift environment. Once the environment is provisioned, the CMDB is updated through automated discovery, monitoring is configured (some through automation), actionable monitored events are converted into incident tickets through integration with ServiceNow and when applicable, issues are resolved through response automation.
Blog post by Ed Wang at NetApp